


The Omega Protocol : Another Manhattan Project
How to safely outsmart a super intelligence

This is a crowdsourced document which was created and edited by readers like you. If you’d like to contribute (even if it's just a typo or a new meme) please subscribe and message Christopher Canal on substack with your gmail. You will be given “comment/suggestion” access to the google doc for this post. Any accepted suggestion means your name will be added to the authors below.
Overview
Many companies around the globe are racing to create machines that are intellectually superior to humans with little consideration for the danger such a technology might pose to humanity. The goal of this project is to mitigate this risk by producing a set of plain english instructions for how to create a humanity aligned Artificial General Intelligence(AGI). We will do this by creating multiple unaligned AGIs within a highly controlled environment where their most optimal action is to produce an alignment procedure. With this procedure, we will then safely build an aligned AGI outside of the controlled environment. There are two KPIs we will use to determine the completion of this project: The aggregate AI Human Benchmark Score and an alignment council’s unanimous vote. We estimate this project will cost about 5.7 billion dollars, and take 3 years to complete from the date when funds are secured. The impact of safe AGI would likely result in an unprecedented economic boom producing over abundance for every human on earth. Prediction markets indicate that there is an 11% chance of extinction for humans by 2030 if we do nothing[6].

Problem Identification
TLDR: The problem is that no one knows how to create an AGI that for sure won’t kill us.
AGI is coming in your lifetime and it might kill you
In recent years there have been incredible advances in machine learning[1]. These advances are likely the reason that AI experts have been changing their minds about when they think human level AI will be created.

An analysis of surveys from Our World in Data[2] shows that in 2018, 22% of AI experts thought that human-level AI was more than 140 years from being discovered. A more recent survey shows that only 6.1% of experts still believed that in 2022. About half the experts guess that human-level AI is less than 40 years out, with several believing it will come before 2030. But who is going to be first to create this technology and why are they building it?
Who is building AGI and why?
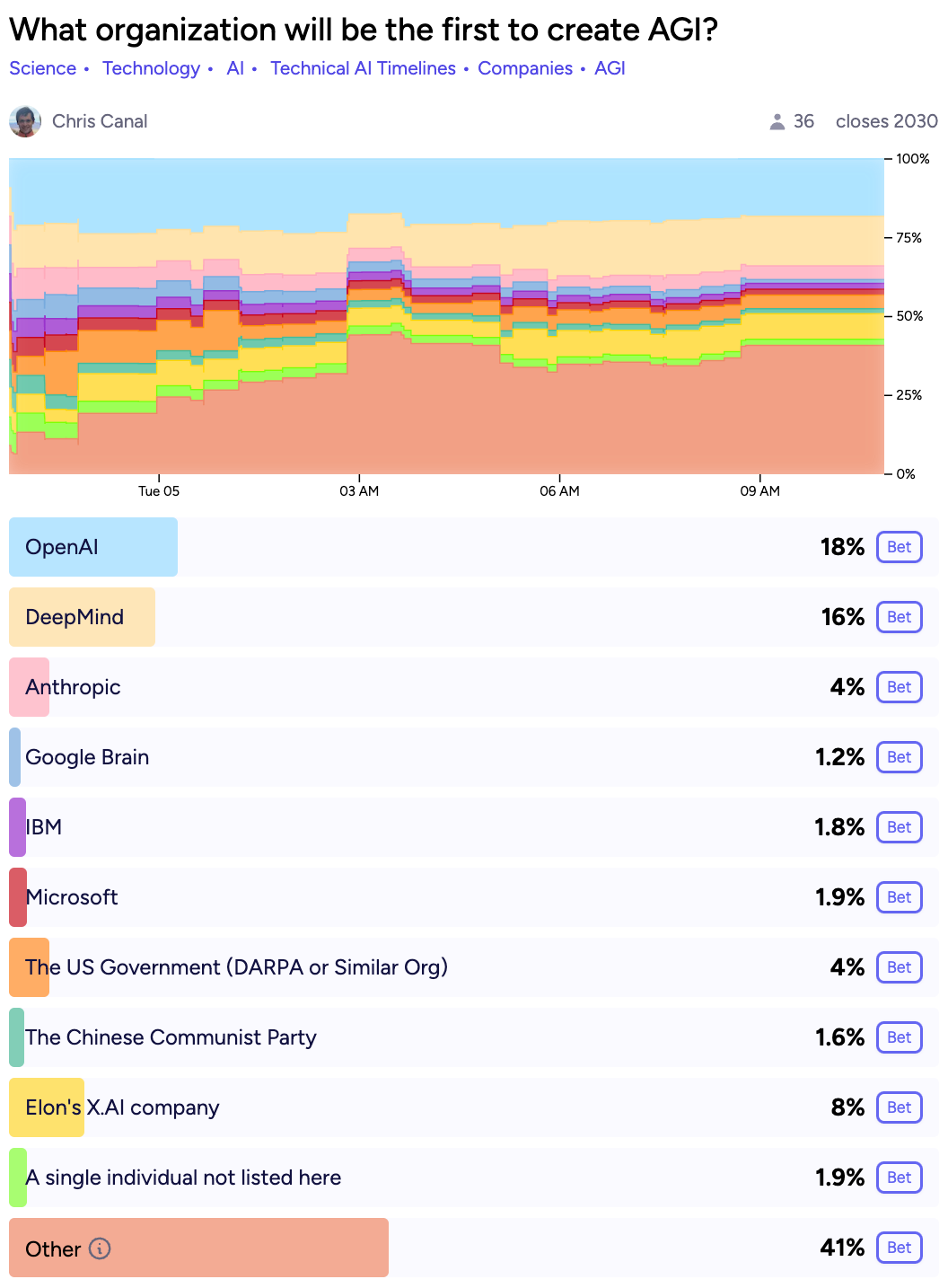
Manifold Markets Prediction[10]
There are at least a dozen well funded companies that are attempting to create artificial general intelligence[3]. Although most of these companies communicate their commitment to safety, they don’t seem to be incentivized to prioritize safety over the race to outperform competitors. For this reason and others Sam Altman, CEO of OpenAI, recently called for global AI regulation[4]. OpenAI is a leader in the race and may be more willing to dedicate time and money to prioritizing safeguards. Competitors who are lagging behind might be incentivized to put less effort into safety in order to catch up in the race towards AGI. These competitors aren’t evil, it's just that the ability to automate most/all employee labor would make any organization wildly successful. Achieving a productivity windfall by being first is enough incentive for many organizations to skimp on safety.

Meme Credit[9]
This race to the bottom dynamic, sometimes called the Moloch Meme[8], makes it difficult to trust private enterprise to develop this technology. Most people would prefer an AI development method that avoids incentives that increase existential risk. After all, if the first creator messes it up, everyone could die. Which is a good segway into the next part of this problem: given that we can actually make human level AI, what are the chances that it wipes out humanity?
How likely is an AI doomsday actually?
Existential risk from AGI is surprisingly likely. Especially when compared to other risks that governments and organizations currently spend billions trying to mitigate.

Prediction markets indicate that there is about an 11% chance of AI wiping out humanity by 2030 [6]. I take this to mean that the general public doesn't trust that AGI will be created safely by the companies known to be working on this. Additionally there is the concern that an AI of a human level of intelligence may be able to self improve itself to be far beyond human intelligence. This intelligence explosion could lead to an AI that cleverly tricks people into building technologies that the AI can use to gain more control over the world (e.g. advanced nanotechnology), which it then uses to accomplish some unknown goal[11]. You might think that you can’t be fooled into building weapons for a robot, but are you sure that your competitors or adversaries would also resist?

There are still some experts who think extinction due to unaligned AI is "preposterously ridiculous"[6], but these experts are the minority. Eric Schmidt (former CEO of Google) said in a recent interview that a superintelligent AI is thought by many people to be “4 to 5 years out”[7]. Schmidt also expressed his concern for the danger that more advanced AI could pose to public safety.

What’s even crazier about this problem is that governments pay tens of billions each year to mitigate Nuclear War[13], and the risk of extinction from nukes over the same time period is only 2% according to prediction markets[12]. At the very least governments should begin enacting policies that reduce AI risk (e.g. restricting giant training runs[14]).

But what are the specific reasons an AI might harm us?
It would make sense at this point in time to divert a significant portion of the US defense budget to rogue AI prevention. But what should we precisely be spending that money on? Well, for starters we will need to break down AI risk into more approachable subproblems. Luckily, one of the leading AI Alignment researchers, Paul Christiano, has spent a significant portion of his research time identifying these subproblems and proposing solutions[15]. Explaining all of these problems is beyond the scope of this document, but this graphic from Christiano provides an overview of some of the known subproblems that will likely need to be solved for AGI to be created safely.

At this point, you have the most critical details of this problem loaded into your mind. Reading beyond this point in the document may bias you further with our approach/solution. Now is the time to comment, or make suggestions if you have them. If you think you have better ideas, or more optimal wordings, or even better memes for this document, we encourage you to collaborate with us via this google doc. Your suggestions might help save the human race! If your suggestion is added to this document via one of the moderators, your name will be immortalized in the authors section below.
If you’d like to further understand the subproblems in AI safety before commenting, aisafety.info is a great place to dive in[4]. We recommend Concrete Problems in AI Safety if you prefer to learn by reading science journal articles[16]. Rob Miles’ youtube channel is a fun resource for those who prefer to learn through educational videos[17].
Solution
TLDR: We will construct an AI containment zone where we create multiple isolated AGIs that might be unaligned. Then we will use each AGI to independently generate candidate alignment procedures which will be verified by top scientists and the other AGIs in containment. The project is complete once a procedure is unanimously voted safe for humanity by the alignment approval council.
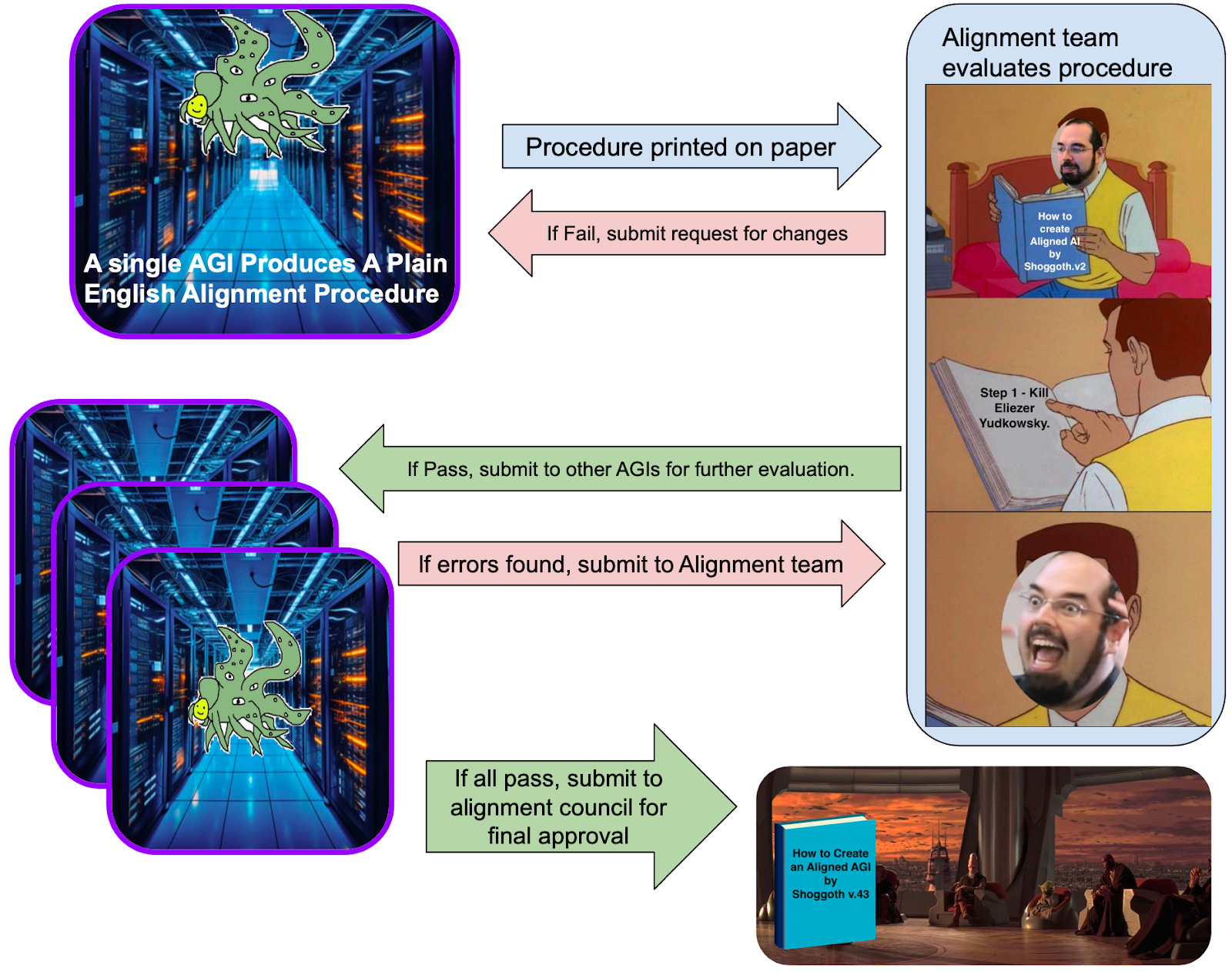
The Omega Protocol : Another manhattan project
Our solution to the alignment problem is to create another Manhattan Project but for creating safe AI, codename: The Omega Protocol. Like the Manhattan project, we will gather the world's top engineers and scientists into a single organization and then rapidly advance the dangerous technology in a controlled setting. We will first build multiple AGIs in an air gapped containment zone. We will then create a game dynamic that pits those AGIs against one another. We will provide a reward to each AGI when they solve subproblems of AI Alignment. We will also provide a reward when one AGI pokes holes in another AGIs solution to an alignment or capabilities problem. It is critical that this highly controlled alignment game is the only way each AI can receive reward. Attempts to escape the containment zone or collude with other AGIs should result in deletion.

Once we study these AGIs and utilize their intelligence to produce instructions for how to build an AI that won’t destroy humanity, we will destroy the AIs and all the hardware in the containment zone to ensure that these unsafe AIs are never released. The instructions for how to build a safe AI is the only output of this project.
If we can contain a superintelligence, our alignment game could potentially solve all capabilities, safety, and systematic problems in AI. This project is also a mechanism for gathering the top talent into a single organization to avoid the unsafe AI race mechanic. As crazy as this plan sounds, we think it is currently the best option humanity has for reducing the probability of extinction.
Design Specification
We have divided our solution into six distinct, but not sequential steps: hire, build, stage, research, iterate, implement. This is not a final design, and is meant to be a starting point from which we can create a plan that effectively reduces AI existential risk.
High Level Overview
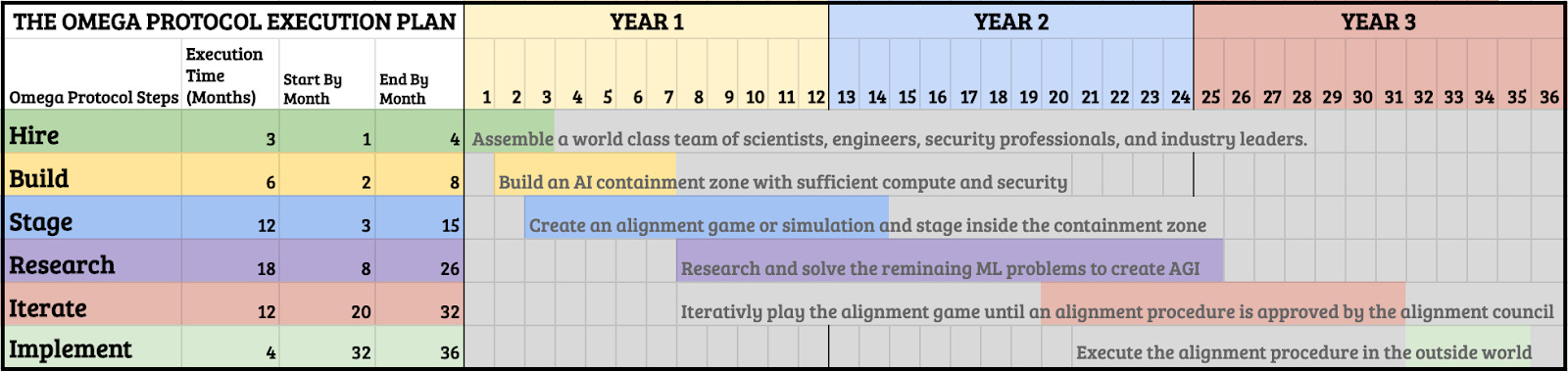
Hire
The deadline for completing this project is the day that a company or person first turns on an AGI with access to the internet. That could be tomorrow or in 10 years from now, but if we hire the people who are most likely to create AGI we might slow the progress of the organizations they are leaving. Therefore it would be a good strategy to hire as many leading AI capabilities researchers as possible in order to decrease the time it takes to complete this project and simultaneously slow down external companies. The timelines in the above Gantt chart assume we recruit the world's top computer scientists and engineers.
Our strategy also hinges on having multiple independent teams of researchers creating separate AGIs which must be uncertain of each other's goals. There may be a few breakthroughs which should be discovered by each team independently in order to make AGIs that are sufficiently different from one another such that cooperation between AGIs is not optimal. This shifts the burden of work from things we are bad at (figuring out alignment) to things we are good at: improving AI capabilities, building secure facilities, and iterating on security protocols to reduce risk.

So we need people who are good at building and enforcing security protocols, people good at AI research, and industry leaders good at building and running large scale projects. We’ve divided our required human resources into four groups: A site security team, a personnel security team, an R&D team, and Partner Organizations.
Site Security Team
This team will design, build, and run the facility that houses the offices, servers, and utilities needed for this project. We imagine that there would be some TSA like interface where we check to make sure that no data is transferred into or out of the AGI containment zone. Based on the 1 to 40 ratio of airline passengers screened per TSA agent each day in the US[18], we would need 8 security screening professionals to screen the 668 people that we expect to enter the AGI containment zone each day. They would look for notes, usb drives, any metal that could contain charge or data, and ensure that it does not leave the containment zone.
The facilities would be built by contractors. The most impressive datacenter construction speed that we found record of was CyrusOne’s Sterling II data center, which was built in 180 days, and would be large enough to facilitate all 668 staff, their work stations, and supercomputing clusters[19]. We would need more specialized facilities than their prior projects, but they seem apt to hire the necessary specialist subcontractors for our sound proofing and radiation proofing needed to create the AGI containment zone.
Personnel Security Team
This team will interview and certify new employees as unlikely to leak data. They will also monitor everyone who enters the AI containment zone, after they leave the containment zone each day. Their job is to protect the people entering the containment zone from bad actors outside of the facility. Their job is also to ensure that personnel are not intentionally or accidentally leaking information from one of the AGIs to the public internet. We could build a team of PIs and Security Guards to track and keep track of all personnel, but it would probably make more sense to partner with the NSA or other government organization that has already built an expertise in monitoring and protecting people.
The Tech Team
This team would be difficult to contract out like the others. These individuals will create the world's first AGI, and then persuade it into producing an alignment procedure. We need at least two of these teams, for there to be two AIs to check each other's alignment procedures; however, we are recommending four teams for redundancy. We think each team should have the following personnel:
1 Project Lead
1 Operations Lead
1 Security Lead
2 Electrical Engineer
2 Systems Engineer
10 Managers
10 Theoretical Computer Scientist
10 AI Safety Researchers
10 AI capabilities Researchers
10 Applied Scientist
10 Executive Assistants
20 Game Developers: Engineers with expertise in creating games and simulations.
80 Software Engineers: UI, UX, Data Engineers, Backend, and Cloud Engineers.
The core people are the researchers, but we think that having several engineers and assistants will minimize stress, and enhance productivity of the top minds.
Public and Private Partners
We think that it is unlikely that a private company alone will be able to enforce strict enough security protocols to contain a possible super intelligence. But we also think that it will be difficult to curate enough GPUs and human talent without private sector collaborators. The obvious candidates are the United States Government, OpenAI, Elon Musk, Deepmind, and Anthropic. There are dozens of organizations and individuals that could help make this project more likely to succeed not named here.
How will we get the best people on this project?
Pay, prestige, and equity. First, we can and should pay them more than anyone else. This is actually quite easy considering the output of this project can automate all white collar labor. The value would easily be in the trillions of dollars per year. Moreover, the value of not going extinct is priceless to most humans. That being said, if we doubled each recruits current salary, that would only cost about 432 Million Dollars per year in salaries, which is far below the amount spent on maintaining our nuclear arsenal[13].
Many of the top minds in computer science are already flush with cash, making it difficult to persuade them with money alone. For these individuals we must rely on the potential prestige of this project. They will be working with the greatest minds alive today on the most important project that humanity has ever undertaken.
Another potential incentive is to guarantee them equity (partial ownership) of the output of the system, which should translate to an unfathomable amount of wealth in the future.
How do you identify who are the top science/engineering leaders?
There are some obvious choices: Yoshua Bengio, Geoff Hinton, Ilya Sylskever, Sam Altman, and Elon Musk to name a few. Many talented scientists would follow any one of these individuals if we convinced them to lead this project. They have already proven that they can recruit the top intellectual talent of the world. With the added prestige and importance of this project, one of these leaders will be able to recruit the team we need to be successful.
Build

We need to be able to contain a being that may be much more competent than any human alive. In order to better understand this problem, we imagine the limits of intelligence when it comes to escaping a containment zone. It seems unlikely that an AGI running on a computer in a sealed lead box beyond the event horizon of a black hole could do damage to humanity. On the other extreme, an AGI running on a server inside the whitehouse, with access to the internet, may be able to cause armageddon with a few simple hacks. What if we allowed the AI in the lead box to print out a message on a piece of paper, limited to the length of a tweet, and then we tossed the AI into a black hole?

Could a message this short destroy humanity? Probably not. When the message becomes as long as a couple million lines of computer code, things start to feel pretty unsafe. It seems like a superintelligence could describe what systems are needed to build an aligned AGI in about the length of a book. So we think the balance is about 80,000 words printed on paper in plain english with zero executable code. Still enough to be dangerous, but manageable for a single person to interpret in one day.
The AI containment zone also takes advantage of the uncertainty that the AGIs will have regarding the number of physical layers between its servers and the outside world. We propose building containment zones within the containment zone, with engineered vulnerabilities at each layer except the outermost layer. These fake containment zones will contain false signals from fake AGIs and/or humans that the AGI might attempt to exploit. If it is detected that the AGI has made an attempt to exploit a vulnerability or manipulate someone outside the innermost containment zone, that AGI will be deleted immediately.

What are we building?
We are building an AI containment zone where we can safely create superintelligence. We will build four GPU clusters (25k H100s each) in sound proof enclosures with no wires and as few radiation paths to the surface as physically possible. These clusters are where AGIs will be trained and tested. At current GPU Prices I estimate this to be around 3 billion dollars per cluster. This datacenter will be different from any other: there will be no digital path to get information out of the facility. This minimizes the chances of weights or AGI written programs being leaked.
We should take extreme action to make sure that no signal gets out of the containment zone. Going as far as creating an equal load for the generator so that the heat produced is constant regardless of compute load. No one from the outside of the building should be able to tell when a heavy compute job has started.
Cluster Read: Data can only be transferred in via physical drive, carried in and connected permanently to the cluster. Removal of drive should destroy it: possibly with thermite or magnets or some other mechanism.
Cluster Write: The cluster can only write to physical paper. It can only write non executable pseudo code, math proof, and natural language. The output must be shorter than 500,000 characters. And each instance of AGI can only produce one output before being destroyed.
Hardware Safety: All Hardware will be destroyed after an alignment protocol is approved by the alignment council. These AGIs may be dangerous to release into the real world and we don’t know how they might cleverly hide their weights on various hardware.
Hardware requirements
There are a few dimensions along which it would be most useful to contain a superintelligence given our scenario presumes some human-intelligence interaction. It’s critical to understand that both incoming and outgoing information pose risks to the experiment, and could advantage the superintelligence. Infrastructural and organizational solutions are useful to ensure fidelity.
Human and analog information vectors.
We’ve identified 9 ways that an AGI might attempt to sneak out information from the AI containment zone: EM Radiation, humans, physical wire, vibrations, water flow, sewage flow, airflow, fuel flow, alignment protocol papers.These information pipelines dictate the design of the AI containment zone.
EM Radiation - It’s conceivable that a superintelligence with sufficient understanding of its component parts could use them to measure and create EM pulse signals in an attempt to transmit and receive messages and information from the outside world. EM is an area where humans lack the competitive advantage in sensory and manipulatory tools, so we would likely turn to brute environmental control to increase the costs of EM attacks. We can create heavy shielding around the containment zone. It would likely be necessary to enclose the building in a layered system of lead linings, faraday cages, and listening stations to detect when and where each layer may have been breached. A Russian-nesting-doll style of EM insulation, monitoring, and even bait/counterattacks could help us detect and react to EM system breaches, and enact a shutdown or reset procedure before the intelligence has time to sufficiently probe the next layer.
Humans - The 668 R&D employees will be going in and out of the containment zone every day. The humans are not only one of the weakest parts of the system, they are also likely to have the highest exposure to the AGIs. However, humans also have a high ability to monitor and control each other, with lots of existing systems to serve as precedent. Those selected to participate in the experiment will be uniquely qualified and informed about the risks of communication with a possibly unaligned superintelligence. For this reason, we think it makes sense to focus on strengthening what we see as our competitive advantage.
Physical Wire - In an existing structure, old and abandoned systems such as dial up lines could represent pathways for a leak. This is only relevant if we refurbish an existing datacenter instead of building one from scratch. The hijacking of power transmission lines could also be a way for an intelligence to transmit or monitor signals to/from the outside world. We can avoid this problem by using generators inside the containment zone to power the cluster. This way only diesel fuel goes in, and emissions go out.
Vibration - Sound from the outside world could contain information and sound from within could be picked up by parallel compute clusters.
Water/Sewer Flow - It’s possible that information could be given away by the variable flows of water/sewer utilities. Deviations from a normal diurnal curve could clue an intelligence into the fact that fewer/more people are using the facility, that project timelines had been changed, or that its perception of time had been manipulated. If an intelligence gained control of these systems or influenced the human’s use of these systems, they could embed signals within the diurnal pattern.
Air Flow - It’s possible that small changes in particulate concentrations in the air within the containment unit could impart information to the intelligence that we would not want in the training data.
Fuel Flow - The AIs will have control over many GPUs which they can utilize more or less of. This could change the fuel consumption in a way that creates a pattern. If a pattern is noticed by a nosy adversary who converts the pattern into code or language that could start a sequence of events that lead to a containment zone leak. Far-fetched maybe, but it can easily be prevented by adding a fake load to the generators when the cluster is not fully utilized so that there is a constant load and constant demand for fuel.
Alignment Protocol Papers - The final output of this project is a set of plain english instructions that will tell humans how to build safe AGI and maintain a world where no unaligned AGI can be created. In these instructions it's possible that a secret code or message could be encoded. This vulnerability is mitigated by the adversarial AIs in the containment zone, which should be heavily incentivized to discover such a message.
It’s important to keep in mind that implementation of all solutions presented would be bounded by project budget and time to criticality of capabilities process in the outside world. If the budget can be ballooned while outside progress is slowed by talent acquisition and regulation, more extreme measures become possible.
With the proper isolating infrastructure, design such as those shown below might resemble what each team would see from inside their unit.

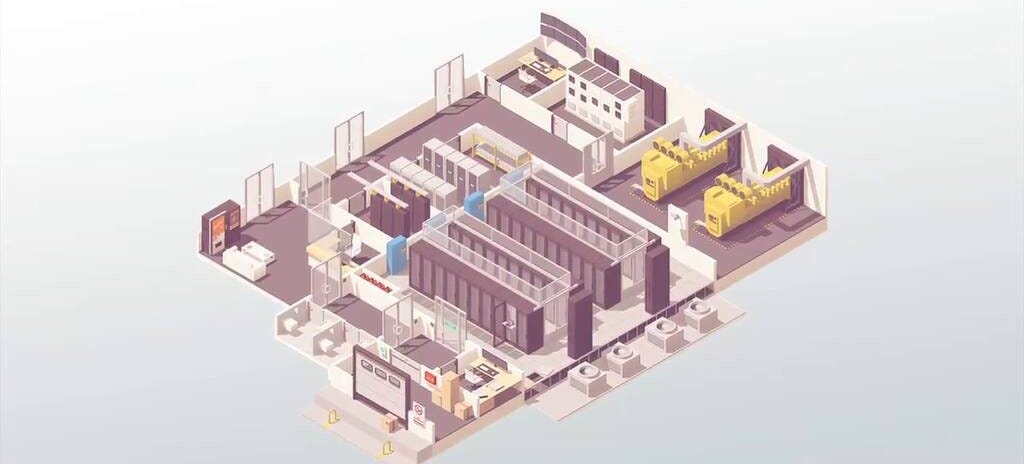
Real Estate Requirements
When thinking about this problem, we first wanted to look at what the minimum viable unit of this experiment is. That means one team running on one compute cluster in one containment zone. We assumed 1 team of 5 people enter the containment with the required systems to function largely independent of the outside world for 6 months at a time, or about 200 days. The space required would roughly be equal to (Office space + Compute Space + Facilities + Utilities + Storage + Security). Adding a buffer for containment and a 1.5x Factor of Safety, we estimate that each unit (a scalable unit representing what it would take to get 1 try at the problem) would take up about 60,000 square feet. Each unit could use up to 1MG (4,400 m³) of water a day, assuming the same amount of compute is needed as was necessary to train GPT-4 in a 100-day timeframe. For this reason an enormous reservoir would have to be found (or built) to retain the almost 200 million gallons of water that would be required to cool the building for our 6 month time horizon. Assume this data center could be built in <180 days. Due to the already efficient nature of the building processes employed in industry today and the likelihood of prerequisite tasks gating each other’s completion, it’s likely that we could expect a stand-up time of 90-120 days, assuming the GPUs were on hand.
See our calculation doc for more info on these estimations.
Alarms
A system of security and surveillance would need to be put in place to make sure that the experiment is conducted safely. These alarms provide a way to shut clusters down for reflashing hardware, or even destruction of clusters in order to prevent containment zone leaks.
Surveillance alarms would sound if project members intentionally or inadvertently leaked or became vectors for information from within the experiment. Depending on the degree of separation deemed necessary between experimental states and between the experiment and the general public, an alarm may sound when different barriers are crossed.
Behavioral alarms might sound when experimenters deviated from their routines by large margins. Such deviations could indicate a manipulation by the superintelligence.
Infrastructural alarms may sound when containment is breached or when a red-herring / honeypot trap is probed by the intelligence.
Distributional Shift Alarms may sound if the environmental controls deviate from their normal operational patterns, or if anomalous patterns are detected within the compute center.
Other alarms may have to do with the conditions of the outside world. If it is suspected that a superintelligence is emerging elsewhere, the facility may have to go into lockdown and continue their work in isolation, hoping to verify a result before anything bad happens.
If residual information is detected to carry through from one state of the hardware to another, this would indicate that the experimental instance has been contaminated by a previous model and would sound an alarm.
Stage
A simple AI containment zone is not enough to contain something smarter than any human. We want to give humanity every chance to get ahead. I think many people mistake a powerful intelligence for an omniscient god. This causes people to assume that it is impossible to predict a more intelligent being's actions. This is simply not true. In certain domains a fairly incompetent person or bot can find the optimal set of actions: think tic tac toe, or the optimal algorithm to run a thermostat. In these situations a super intelligence that had the goal of winning a single tic tac toe game would likely make the same moves as a competent child. I think the important consideration here is the dimensionality of the game world that the AI is created in. I don’t know what the optimal game or simulation is for containing and directing the super intelligence, but it needs to strike a balance of enough real world data to train an algorithm to be as competent as a human, but also limited enough that the true dimensionality of the world is not exposed. The simpler the world that we create for an AI, the more likely we will be able to predict and direct its actions.
Research
In this step, the R&D teams will create AGIs that may or may not be aligned inside the AI containment zone. Ideally there will be 4 R&D teams that use mutually exclusive training data to create their AGIs. Mutually exclusive training sets, and varying architectures increase the chances that the terminal goals of the AGIs are differing and competing. This will decrease the chance of coordination between the AGIs. Coordination could cause the Alignment Council to be fooled by an alignment procedure that has an encoded message or somehow organizing an AGI escape plan.
The research still required to create an AGI is probably the most open question in this document. This section has a very high chance of being wrong. I’ve made an attempt at guessing what is missing from current LLMs that would enable them to do any job that a human could:
Thought loops
MultiModal internal vectors
Forward pass weight updates or autonomic retraining
A way to automatically create drivers to sensors and actuators
Probably a way to distill a large network weights into a smaller network’s weights
A more efficient way to store memories
Thought Loops
All thinking animals seem to have a variable amount of time between inputs and outputs. This allows a single thinking system to amplify its power. This process involves the capacity for self-reflection and feedback loops that allow an intelligent agent to process information iteratively with the same neurons. Current LLMs rely on input-output systems, meaning they lack the ability to engage in internal reasoning and learning without external input. Developing thought loops in LLMs would enable the system to analyze and refine its thought processes autonomously. I think this would look similar to the gating mechanism in LSTMs but instead of an input/output/forget gate, I think there should be a continuous sequential thought vs output action gate.
MultiModal Internal Vectors
While current multimodal LLMs can process different types of data, they still lack the ability to efficiently integrate and reason with this information in a unified representation. Developing AGI likely requires the integration of multimodal internal vectors, allowing the model to effectively synthesize and learn from various types of data simultaneously. For example: the data for the sound of the word “fire”, the text characters “fire” and an image or video of fire all have the exact same vector representation somewhere in the net. This would result in more robust and context-aware decision-making.
Forward Pass Weight Updates or Autonomic Retraining
Traditional LLMs rely on backpropagation and gradient descent to learn from new data, which requires significant computational resources. AGI will need a more efficient and continuous learning mechanism, such as forward pass weight updates or autonomic retraining. These methods would allow the model to learn and adapt in real-time without the need for massive computational power or explicit supervision. Geoff Hinton produced a recent paper but this problem may already be solved.
A Way to Automatically Create Drivers for Sensors and Actuators
For AGI to interact effectively with the world, it must have the ability to autonomously create and manage connections to various sensors and actuators. This will enable the AGI to collect data, analyze it, and then build its own code for controlling arbitrary devices and interfaces, just like a decent engineer would.
Weight Distillation
Large neural networks often contain billions or trillions of parameters, making them computationally expensive and challenging to deploy in resource-constrained environments. AGI would benefit from weight distillation, a technique that compresses a large network into a smaller one while retaining most of its performance. This would allow AGI to operate efficiently and adapt to different contexts and environments when making copies. I think it would also allow it to make drivers for new interfaces more efficiently.
A More Efficient Way to Store Memories
Computer databases and data structures store information very efficiently. Current LLMs struggle to achieve similar information efficiency, which is crucial for AGI to possess a human-like ability to learn and remember and retrieve. Humans easily learn new tools for helping them remember, plan, and organize. This may tie in with automatic driver creation.
Iterate
It seems unlikely that the first procedure will be flawless. We may need to destroy AGIs and rebuild with modified data sources or architecture. The alarms we design may alert us to the intentions or strategies of a super intelligence early. There will likely be many deletions and recreations of AGIs inside the containment zone. An iterative approach seems like the best way to find AGIs that will cooperate with us enough to generate a reliable alignment protocol.
Implement
It’s hard to know what exactly we will find out in this project. Most of the uncertainty comes from the uncertainty around if the creation of a human level AI always results in a superintelligence explosion. There’s also a possibility that it is impossible to control an agentic AI more intelligent than any human. For these reasons, this section is highly speculative. Here are some ways I think this can go:
Technological Utopia with Police State Undertones
After leading the Omega Protocol for 3 years, Elon Musk presents the results of the Omega Protocol with the UN. The people who funded the Omega Protocol project become enormously wealthy, although in a post-scarcity society this only gets you social status, so they are more rewarded by the fact that their investment made humanities survival possible.
Elon explains that the alignment procedure requires the cooperation of every country in the world to commit to using only a specific set of optimizers when training machine learning algorithms. If we guarantee that every country follows these rules, we will automate all labor and transition to a world of abundance. Still need to figure out a reasonable distribution of wealth and resources for each human on earth, but that's a good problem to have. No more work, yay!

Anti-AI Alliance
The Omega Protocol project proves empirically and theoretically that it is impossible to create a human level AI that will reliably serve humans. Ilya Sutskever meets with US President Biden to explain the implications of this research.

Sutskever convinces the President that we must use whatever means possible to ensure that no one creates AGI. This creates a more unstable world, war is more likely, but most humans will live. Transitioning to a government that enforces rules in my jupyter notebooks is gonna suck.
Costs - $5.7B

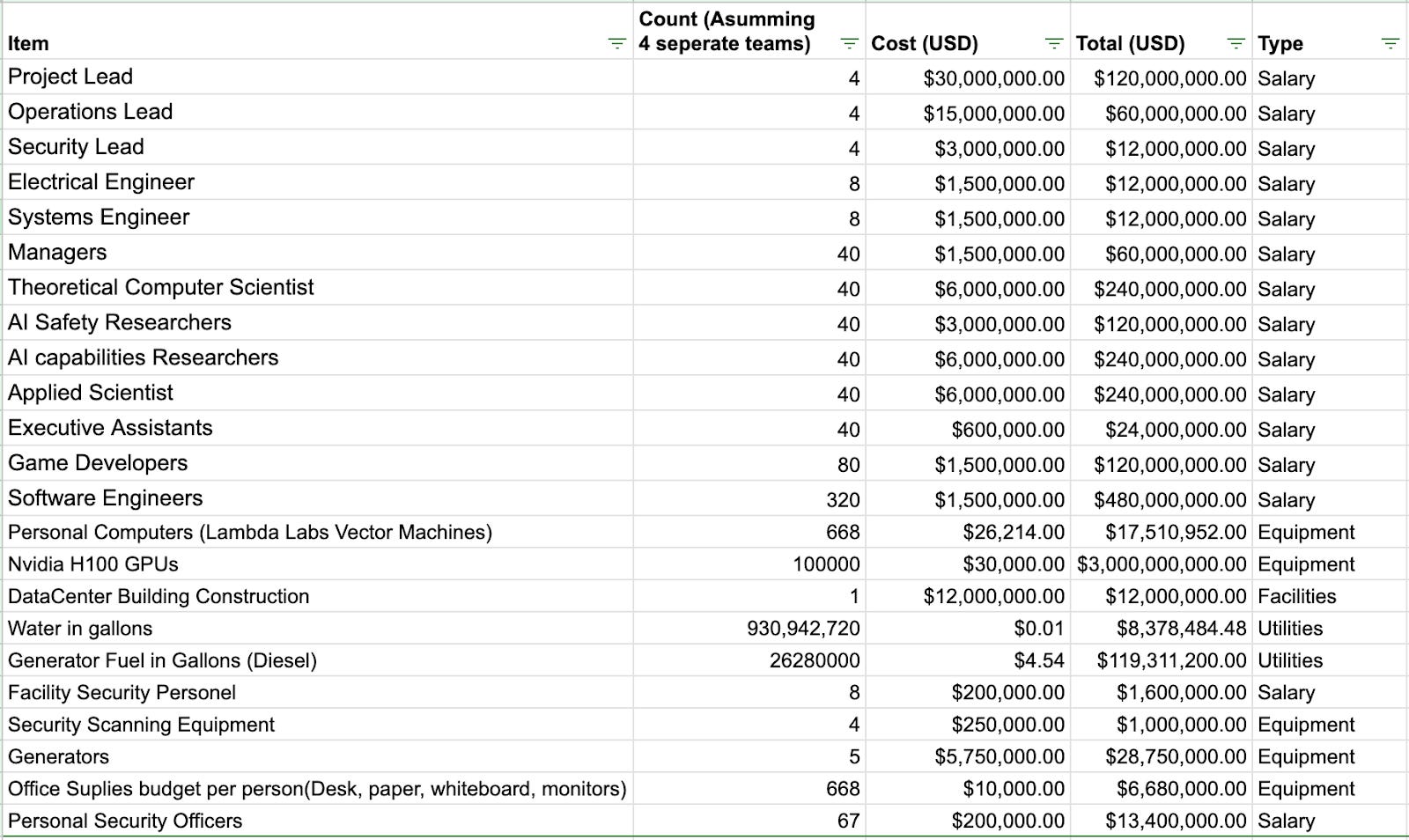

Funding
The funds required to complete this project are relatively small compared to the budget of major companies or the yearly expenditures of the US Department of Defense. This project might be able to be executed by a private company, but the project would likely go fastest if it followed a spacex model: government and private funding but run as a private enterprise. An industry leader backing the project could help it easily secure the funds we need to execute this plan.
This project could vastly change the course of humanity, so it would make sense that every human has an opportunity to invest. Crowdfunding that includes non accredited investors should be considered.
Failure States
It’s important to think about some possible failure states so we can prevent them and know when it’s time to shut down one or many of the parallel instances of the experiment. These failure states also inform us about where we should implement alarm systems.
Failure to isolate experimental states from one another:
When running multiple superintelligences in parallel, it would be key to isolate them from one another. Were one intelligence gain the ability to communicate with another, they would have to be merged into one for the experiment to continue. We want to maximize diversity in approaches and outcomes.
Similarly, the teams that interact with the superintelligences should not be allowed to interact with each other, and optimally would not even be aware of the specifics of other parallel teams. This is to prevent our approaches from converging too much. Were they to converge, the surveillance records of the staff and their communications ought to be reviewed to rule out collusion and make sure the convergence is naturally occurring. The containment ought also to be reviewed, as the intelligences may be converging as the result of intelligence to intelligence collusion, without the teams themselves communicating.
Failure to contain a superintelligence from the outside world: What happens if it transmits itself to some outside network where it is uploaded to the internet? Even if it is not parsed in a way that will run, its logical structure and state can sit dormant for years until something runs it. This is very bad, because the point of containment is to give researchers the freedom to try risky profiles.
Failure to accurately measure and/or interpret changes in the superintelligence. If no tools are developed to provide a sufficient check on results, the experiment will never be able to safely conclude.
Failure to coordinate enough global compute and/or talent such that the emergence of a misaligned superintelligence happens outside of the experiment’s control.
Failure in assuming alignment is possible. It could be a problem if at some point in the experiment we prove that alignment is not possible but that superintelligence is.
Failure to convince the intelligence to cooperate and/or comply with researcher’s attempts to study it. Too much scrutiny might breed deceptive and manipulative intelligences. By creating an intensely hostile environment to house the superintelligence, we may be inadvertently training it to evade our best tools and negate our best countermeasures.
Action Items
Get feedback from experts on this approach and iterate on the design
Create pitch deck based on approach and pitch to industry leaders
Appendix
Assumptions
What are the assumptions that you have made in this solution? Can you point to why you have these assumptions? Link if possible.
Unaligned AGI has more of a chance of destroying humanity in the coming years than Nuclear War - As of August 27, 2023, prediction markets have the probability of Nuclear War wiping out humanity by 2030 at 1.8%. The market sets the chance of AI wiping out humanity by 2030 at 11%. Our countries and institutions have invested trillions in preventing and strategizing to avoid nuclear war, but almost no serious effort towards preventing extinction from rogue AI.
Solving Alignment is an Instrumental Goal - Self improvements to an existing AGI must be done carefully in order to account for value drift. It is likely that all AI’s have the intermediate goal of solving alignment. For self improvement to be a viable instrumental goal, each AGI must be able to trust that future versions have identical terminal goals. Only then can they reliably make copies and create specialized or improved versions of themselves. Given this dynamic, we should expect all AGIs to have the intermediate goal of solving alignment no matter their terminal goal. By ensuring that we create multiple AGIs that are uncertain if the other AGIs have identical terminal goals, we provide an incentive for AGIs to produce alignment procedures, and attempt to disapprove other AGI or human produced alignment procedures.
We can make at least two AGIs with different and competing terminal goals - It is unlikely that we will know for certain an AGIs terminal goals at the time of creation, but it seems likely that they will be at least slightly different from other AGIs if the training data and or architecture is different. Mutually exclusive training sets and different architecture seems likely to produce different terminal goals. Multiple AGIs cooperating against humanity in this project could lower the probability of success. The worry is that an AI will send hidden messages to another AI in an unverified alignment procedure which coordinates actions that result in a data leak from the lab to the outside world. Because these AGIs are likely misaligned with humanity, there is an incentive to deceive humans and agree that the alignment procedure works, when it actually has built in vulnerabilities.
Solving Alignment Means Producing a method to Build Safe AGI and Restrict Other Humans from Creating Unsafe AGI - Although its possible to create an alignment procedure without creating AGI, our approach will be to use AGI to create an alignment procedure: the output of the project produces a procedure to create an AGI that is aligned. It’s also likely that other humans will continue reckless development of AGI outside of this project, so the alignment procedure produced will need to include steps to continuously govern and restrict those external teams or states.
Metrics
The Aggregate AI Human Benchmark Score
Many LLM researchers have been developing tests to evaluate and compare models. Hugging face has created a great interface for quickly scoring these models[1]. We think this can go further. We propose combining every vision, audio, language, and game playing test into a single AGI test. This test should include a human benchmark for each of the tests. Surpassing human level scores on all tests in all domains with a single algorithm would signal that AGI has been achieved. Then the AGI should begin to play our alignment game.
The Alignment Councils Unanimous Vote
There have been a few geniuses thinking about the problem of alignment for over a decade. These experts may have the best chance of finding flaws in the AGI developed plan. I’m not sure who should be on this council, but I think it should be more than 4 people but less than thirteen. It almost certainly should include Paul Christiano, Eliezer Yudkowsky, Nick Bostrom, Ilya Sutskever, Chris Olah, and Yoshua Bengio.
Definitions
Artificial general intelligence (AGI) - An artificial general intelligence (AGI) is a hypothetical type of intelligent agent. If realized, an AGI could learn to accomplish any intellectual task that human beings or animals can perform.[22]
Superintelligence - A superintelligence is a hypothetical agent that possesses intelligence far surpassing that of the brightest and most gifted human minds.[23]
Alternative Solutions
Refurbish existing data center to have an AI containment zone: Cheaper but it seems risky to depend on removing connections that may be underground or in concrete. Sealing and shielding the facility may be difficult as well.
Let Sam Altman and his team solve Alignment. Hope they get solve before its too late and that AGI happens to be very friendly towards humans regardless of its objective function.
Stakeholder Feedback
Nothing here yet.
FAQ
Nothing here yet.
Past Document Versions
Sources
Beeching, Edward et al. "Open LLM Leaderboard." Hugging Face, 2023, https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard.
Roser, Max. “Ai Timelines: What Do Experts in Artificial Intelligence Expect for the Future?” Our World in Data, OurWorldInData.org, 7 Feb. 2023,https://ourworldindata.org/ai-timelines.
Glover, Ellen. “15 Artificial General Intelligence Companies to Know.” BuiltIn.Com, Built In, 8 Nov. 2022, https://builtin.com/artificial-intelligence/artificial-general-intelligence-companies.
Miles, Robert et al. Stampy, Alignment Ecosystem, 28 June 2022, https://stampy.ai/
Costigan, Johanna. “OpenAI’s Sam Altman Makes Global Call for AI Regulation-and Includes China.” Forbes, Forbes Magazine, 14 June 2023, https://www.forbes.com/sites/johannacostigan/2023/06/13/openais-sam-altman-makes-global-call-for-ai-regulation-and-includes-china/.
Randall, Martin. “Will Ai Wipe out Humanity before the Year 2030?” Manifold.Markets, Manifold Markets, 5 May 2023, manifold.markets/MartinRandall/will-ai-wipe-out-humanity-before-th-d8733b2114a8.
Zakaria, Fareed. “Video: Fareed Looks at the Brave and Frightening World of AI | CNN Business.” CNN, Cable News Network, 3 September 2023, www.cnn.com/videos/tech/2023/09/03/fareed-zakaria-gps-artificial-intelligence-history-vpx.cnn.
Alexander, Scott. “Meditations on Moloch.” LessWrong.Com, LessWrong, 29 July 2014, www.lesswrong.com/posts/TxcRbCYHaeL59aY7E/meditations-on-moloch.
Memes, AI Notkilleveryoneism. “ AI Notkilleveryoneism Memes.” Twitter, Twitter, 10 July 2023, https://twitter.com/AISafetyMemes/status/1678392463612944385
Canal, Christopher W. “What Organization Will Be the First to Create Agi?” Manifold.Markets, Manifold Markets, 4 September 2023, manifold.markets/ChrisCanal/what-organization-will-be-the-first-8fc809e01f4a
Urban, Tim. “The Artificial Intelligence Revolution: Part 2.” Wait But Why, 18 July 2023, https://waitbutwhy.com/2015/01/artificial-intelligence-revolution-2.html.
Noonan, Joseph. “Will a Nuclear War Wipe out Humanity by 2030?” Manifold, 4 July 2023, manifold.markets/JosephNoonan/will-a-nuclear-war-wipe-out-humanit-80eb7515b74e.
Bennett, Michael. “Projected Costs of U.S. Nuclear Forces, 2021 to 2030.” Congressional Budget Office, May 2021, https://www.cbo.gov/publication/57240.
Tabarrok, Connor, and Christopher W Canal. “Learning from History: Preventing Agi Existential Risks through Policy.” Learning from History: Preventing AGI Existential Risks through Policy, Of All Trades, 7 May 2023, alltrades.substack.com/p/learning-from-history-preventing.
Paul Christiano: Current Work in AI Alignment.” Paul Christiano: Current Work in AI Alignment | Effective Altruism, Center for Effective Altruism, 29 Aug. 2019, https://www.effectivealtruism.org/articles/paul-christiano-current-work-in-ai-alignment.
Amodei, Dario, et al. “Concrete Problems in AI Safety.” arXiv.Org, Open AI, 25 July 2016, https://openai.com/research/concrete-ai-safety-problems.
Miles, Robert. “10 Reasons to Ignore AI Safety.” YouTube, Robert Miles AI Safety, 4 June 2020, youtube.com/watch?v=9i1WlcCudpU.
TSA Media Room. “TSA by the Numbers.” TSA by the Numbers | Transportation Security Administration, 19 May 2021, https://www.tsa.gov/news/press/factsheets/tsa-numbers.
Moss, Sebastian. “Building at Speed.” Data Center Dynamics, DCD, 10 May 2019, https://www.datacenterdynamics.com/en/analysis/building-speed/.
Metz, Cade. “A.I. Researchers Are Making More than $1 Million, Even at a Nonprofit.” Nytimes, The New York Times, 19 Apr. 2018, https://www.nytimes.com/2018/04/19/technology/artificial-intelligence-salaries-openai.html.
Office of Legacy Management. “Manhattan Project Background Information and Preservation Work.” Energy.Gov, https://www.energy.gov/lm/manhattan-project-background-information-and-preservation-work.
“Artificial General Intelligence.” Wikipedia, Wikimedia Foundation, 4 September 2023, https://en.wikipedia.org/wiki/Artificial_general_intelligence.
“Superintelligence.” Wikipedia, Wikimedia Foundation, 6 September 2023, https://en.wikipedia.org/wiki/Superintelligence.
Dean, Grace. “One of the ‘godfathers’ of Ai Says Concerns the Technology Could Pose a Threat to Humanity Are ‘Preposterously Ridiculous.’” Business Insider, Business Insider, 15 June 2023, www.businessinsider.com/yann-lecun-artificial-intelligence-generative-ai-threaten-humanity-existential-risk-2023-6.
Document Authors
Christopher Canal, Connor Tabarrok, Peter Hozák
Your suggestions are appreciated! If a suggestion is accepted, and you are a subscriber, your name will be added to the authors section of this document. Link to document: https://docs.google.com/document/d/10VS39m2vKJsWFaUwWk5KgQ1TmVsEHjSoZYbx4T0C_n8/edit?usp=sharing
This is a way better safety plan than what will actually be attempted, I predict. So I'd support it if governments were taking it seriously, as a big step in the right direction. The hard part is getting governments to take it seriously.
It could also be that one AGI playing against another realises that it needs to fool the researchers to win and builds a communications gimmick to do so. If it is clever enough to fight, it can be clever enough to deceive, to persuade. If he's smart enough, he can time it. How can this be prevented?